Sparse coded handcrafted and deep features for colon capsule video summarization (IEEE CBMS 2017)
Abstract
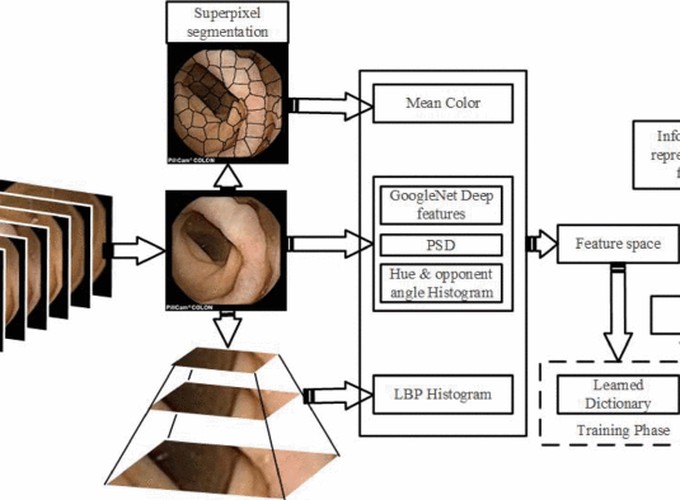
Capsule endoscopy, which uses a wireless camera to take images of the digestive track, is emerging as an alternative to traditional wired colonoscopy. A single examination produces a sequence of approximately 50,000 frames. These sequences are manually reviewed, which is time consuming and typically takes about 45–90 minutes and requires the undivided concentration of the reviewer. In this paper, we propose a novel capsule video summarization framework using sparse coding and dictionary learning in feature space. Video frames are clustered into superframes based on power spectral density, and cluster representative frames are used for video summarization. Handcrafted and deep features that are extracted for representative frames are sparse coded using a learned dictionary. Sparse coded features are later used for training SVM classifier. The proposed method was compared with state-of-the-art methods based on sensitivity and specificity. The achieved results show that our proposed framework provides robust capsule video summarization without losing informative segments.
Ahmed Mohammed
My research interests include medical imaging, computer vision, machine learning.